Every drug discovery organization knows the moment. A CRO delivers a data package — assay results, analytical spectra, ELN experiments — and someone on your team has to deal with it. The compounds are named differently than your registration system expects. The assay conditions use terminology that doesn't match your dictionaries. The NMR and LCMS reports are PDFs buried in a folder. The synthetic chemistry ELN records exist only in the CRO's system, not yours.
So a scientist — or your informatics team — spends hours sorting it out. Then it happens again next week, with the next delivery, from a different CRO with different conventions.
If this sounds familiar, you're not alone. And you're almost certainly underestimating what it's costing you.
Many teams process CRO data with a series of recurring tasks that nobody has officially identified as a problem — and a quiet accumulation of data that never quite got loaded. You might recognize these warning signs:
- You have a folder (or folders) of CRO data that hasn't been properly processed yet — "to be loaded later"
- Scientists are manually copying results out of CRO reports rather than waiting for a proper data load
- ELN experiments from CROs exist as PDFs in a shared drive, not as searchable records in your own ELN
- You can't easily search or compare assay results across multiple CRO partners without significant manual effort
- Someone on your team gets a CRO data delivery and immediately groans
If two or more of these are true, your team is paying the CRO data tax — in scientist hours, in informatics capacity, and in data that isn't as findable or usable as it should be.
The Hidden Tax Nobody Budgets For
When organizations calculate the cost of outsourcing research to CROs, they add up the contract value: reagents, assays, synthesis runs, analytical work. What rarely appears on the spreadsheet is the cost of receiving and processing all that data on the receiving end.
Research published in The AAPS Journal confirms what most informatics teams already know from experience in preclinical discovery: every external partner operates its own data management systems, applies its own naming conventions, and delivers data in whatever format its own platforms produce.
When you work with two CROs, you manage two sets of inconsistencies. When you work with five, you manage five — plus the edge cases that emerge when you try to compare results across them.
The Pattern Behind the Problem
The real cost isn't just in the hours spent on any single delivery. It's in the pattern that develops over time — one that most teams have lived but few have formally named.
The cherry-picking step is worth pausing on. When scientists manually extract the data they need most urgently, the rest of what the CRO delivered — assay conditions, supporting analytical data, compound registrations, full experimental records — sits unprocessed. It exists, technically. But it isn't in your systems, which means it can't be searched, can't be compared, and can't be reused. You paid for it. It's functionally invisible.
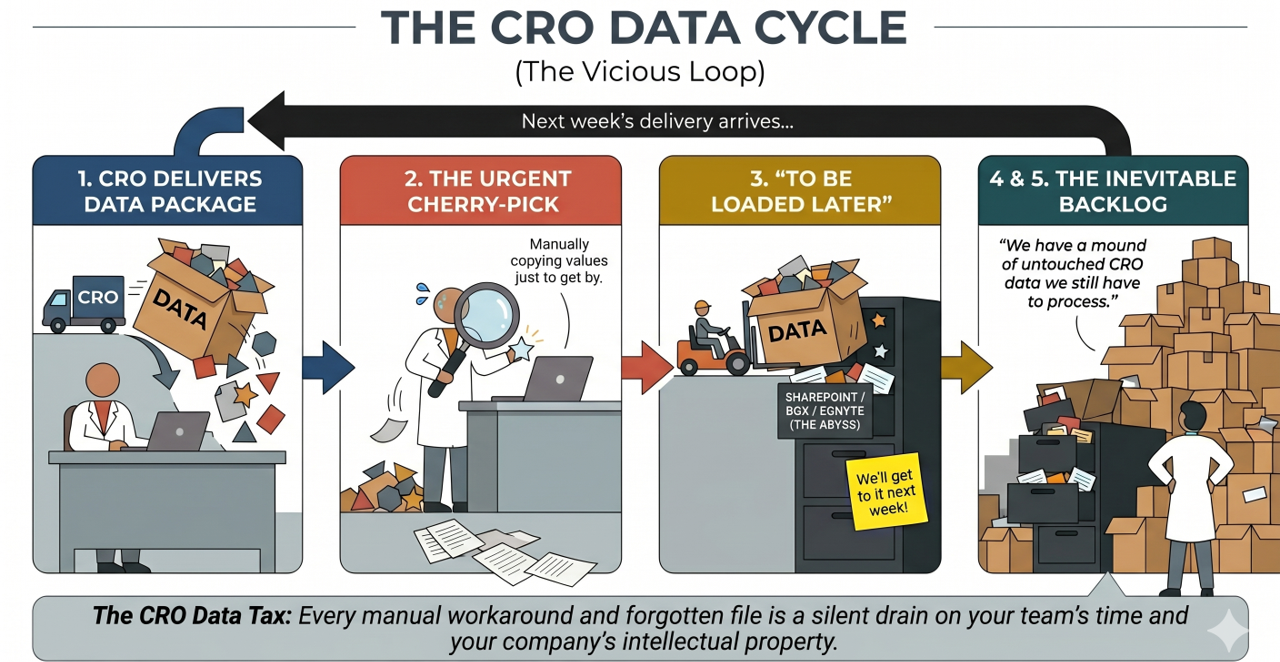
The CRO Data Cycle — every manual workaround and forgotten file is a silent drain on time and IP.
The Problem Behind the Problem: Data That Never Arrives
The time cost is real, but there's a quieter risk that's harder to quantify.
When ELN experiments stay in the CRO's system — because ingesting them is too painful, or because someone quietly assumed it wasn't technically possible — your organization loses something it may never recover: searchable, auditable, IP-protected records of work you paid for. The synthetic routes. The reaction conditions. The analytical characterizations. They exist on paper, or in PDFs, or in a system you don't control.
For organizations operating a largely virtual or delocalized model with heavy CRO reliance, this isn't an edge case. Significant portions of a program's research history can end up living somewhere other than the organization's own ELN. When a CRO relationship ends, when a key contact leaves, when a legal question arises about compound provenance — those gaps matter.
The registration challenge compounds this further. Compounds arriving with inconsistent identifiers, or biologics that don't cleanly map to your registration system's business rules, don't just create cleanup work. They create downstream risk: duplicate registrations, broken assay-to-compound linkages, data that can't be searched or reused in subsequent programs.
What "Impossible" Actually Means
There's one part of this problem that doesn't get discussed much, because most teams have already written it off.
When we ask scientists and informatics professionals about migrating CRO ELN experiments into their own ELN systems — not just archiving PDFs, but actually migrating the chemistry — roughly half assume it can't be done accurately. Not that it's difficult. That it's impossible.
This belief is understandable. Synthetic chemistry ELN experiments contain chemical reactions: reactants, reagents, products, stoichiometry. When those reactions are exported from a CRO's ELN system and subjected to straightforward programmatic conversion, the results are often garbled — reactions where the correct chemical relationships are technically preserved but all the structural elements are visually stacked on top of each other, rendering them unreadable and unsearchable as chemistry.
Our team encountered exactly this problem. The solution required developing a custom visual clean-up layer combining multiple cheminformatics toolkits — work that most organizations have neither the time nor the specialized expertise to undertake. The result is genuine chemical migration: reactions that are structure-searchable in the destination ELN, not just archived images of what used to be there.
The significance of this is worth stating plainly: synthetic routes and reaction conditions captured in CRO ELN experiments represent real IP. If those records are sitting in a folder as PDFs — unsearchable, not structure-indexed, not connected to your registration data — you have them but you can't use them.
The problem
CRO ELN systems (such as Revvity Signals, used by many synthesis CROs) export chemical reactions in .rxn format — a variant of the standard .mol file structure. When these reaction files are converted programmatically using commonly-available cheminformatics libraries such as RDKit, the result is what our team came to call "visually scrambled" reactions: the correct chemical relationships (reactant, reagent, product) are preserved, but all structural elements and visual geometry are stacked on top of each other, rendering the reactions unreadable and un-structure-searchable. This is a known limitation of direct .rxn-to-ELN conversion, and one of the reasons many informatics teams assume the migration simply can't be done correctly.
The solution
Our team developed a custom visual clean-up step that resolves the coordinate geometry issues before the reaction is imported into the destination ELN. This step combines RDKit (rdkit.org) for reaction processing with EPAM's Indigo Toolkit (lifescience.opensource.epam.com/indigo/) for layout normalization — a combination we developed and validated through extensive testing on real CRO export files. The result: reaction records that are correctly rendered, structure-searchable as chemistry, and connected to compound registration data in the destination system.
Why this matters
Synthetic routes and reaction conditions captured in CRO ELN experiments represent genuine IP. A PDF of a reaction is a record; a structure-searchable reaction in your ELN is a usable, searchable, defensible asset. For organizations working with international synthesis CROs, this distinction is significant.
A Systematic Approach: CROW
Workflow Informatics built CROW — the Contract Research Organization Wizard — specifically to address the full scope of this problem. Not as a one-time migration script, but as a configurable, customer-operated suite of tools that integrates with the platforms your team already uses.
CROW is not a SaaS application. It's a set of specialized utilities and services, built from years of accumulated drug discovery informatics expertise, that Workflow configures around each customer's specific environment, workflows, and business rules. The three core problem areas it addresses:
Compounds and Biologics
Normalization and canonicalization of structures received from external partners, followed by ingestion into your registration system according to your business rules. The result is clean registrations that map correctly to your existing data — without the manual review overhead or the risk of duplicate and mislinked records.
Assay and Results Data
Typically, this involves the extraction of results from the summary files and reports CROs actually send — formatted the way CROs actually format them — with standardization of dictionaries and assay conditions using the published BioChemUDM standard. Both fully automated and QC-and-review workflows are available, so your team retains control of what gets committed. Alternatively, we offer a web-based data ingestion portal, which mimics the typical spreadsheets used by CROs for assay data, but enforces controlled vocabularies and data types. This solution feeds a UDM-based data warehouse, and can also automatically load commercial data platforms.
ELN Experiments
Import of external ELN records — including text-searchable attachments and chemically-searchable reactions — into your own ELN system. This includes the custom chemistry migration capability described above: synthetic chemistry experiments with their reactions intact, structure-indexed, and connected to your registration data.
CROW integrates with your existing research data management platforms. It can be deployed as a standalone application your team operates independently, or Workflow Informatics can manage it as an ongoing service — a practical option for teams that want the capability without adding operational overhead.
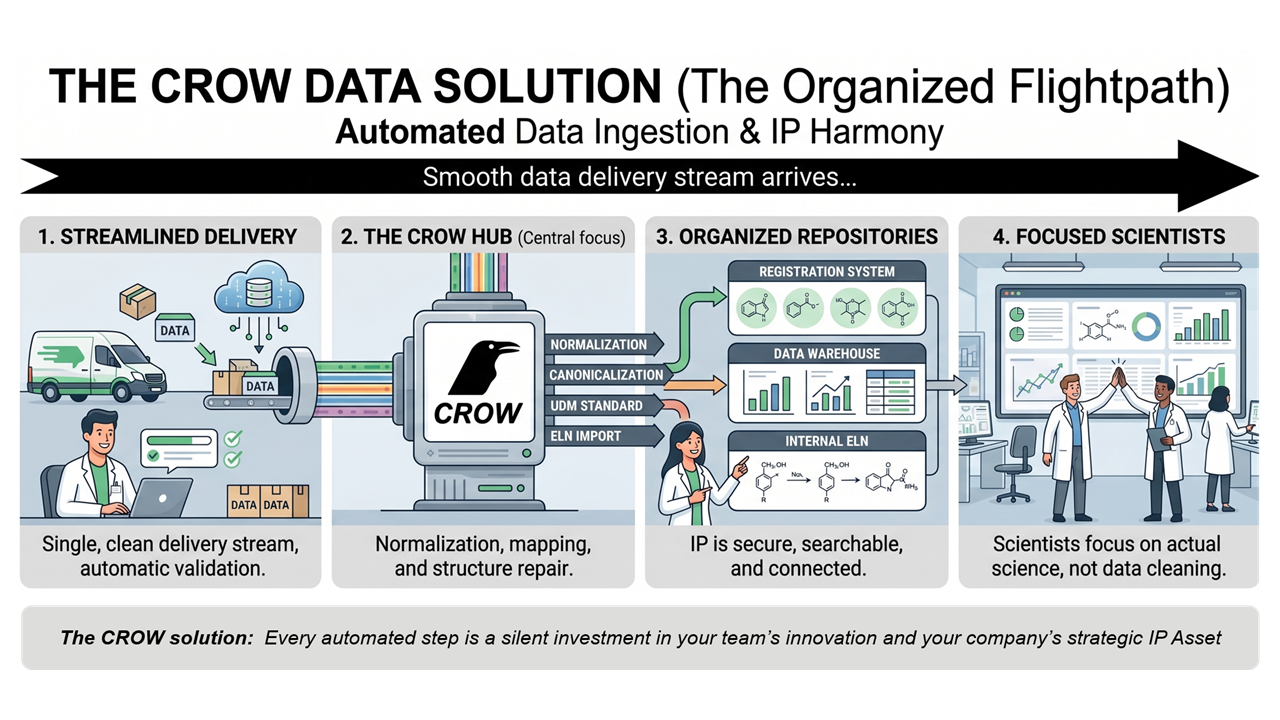
The CROW Data Solution — automated data ingestion and IP harmony, from delivery to discovery.
The Bottom Line
Every hour your scientists or informatics team spends normalizing CRO data is an hour not spent on science. Every ELN experiment sitting in a CRO's system or a shared folder is IP your organization can't search, can't audit, and may not be able to defend. Every compound that arrives with inconsistent identifiers is a registration risk you're carrying silently.
The CRO relationship is a strategic asset. The data coming back from it should be too.
If your team is still spending hours every week managing the aftermath of CRO data deliveries — or if you have a folder of data that was supposed to be loaded months ago — we'd like to show you what a systematic approach looks like.
The Contract Research Organization Wizard (CROW) is Workflow Informatics' suite of tools and services for receiving, normalizing, and ingesting research data from external partners and CROs into your existing research platforms. Originally developed to help scientists overwhelmed by the volume and inconsistency of externally-sourced data, CROW has evolved into a configurable solution covering three core capability areas:
Compound & Biologic Normalization
Canonicalization and ingestion into your registration system, according to your business rules — not generic defaults.
Assay & Results Data Processing
Web-based data ingestion portal or extraction from CRO-formatted summary files, standardization using the BioChemUDM standard, with automated and QC-review workflow options.
ELN Experiment Import
Text-searchable and chemically-searchable ingestion of external ELN experiments — including synthetic chemistry reactions — into your own ELN system.
Deployment options: Stand-alone application your team operates, or fully managed as a service by Workflow Informatics.
Coming soon: A CRO-facing interface to enforce data standards at the source, track requests, and streamline uploads before the data even leaves the CRO.
Learn more: workflowinformatics.com/crow
A highly virtual, geographically distributed biotech — with scientists across multiple countries — runs its discovery program almost entirely through a network of international CROs. The research is productive. But the data coming back from those CROs had become a growing management burden, and a quiet accumulation of unprocessed information was building up in shared drives and folders.
The problem had two layers. First, ELN experiments from synthesis CRO partners — complete synthetic chemistry records including reactions, structures, and analytical characterizations — were accumulating outside the company's own ELN system. Nearly 3,000 legacy records had never been loaded. Second, analytical data files (NMR, LCMS, HPLC-MS) from ongoing CRO work were still being processed manually, one file at a time, falling further behind with every new delivery.
Phase 1: The ELN Migration
Working with Workflow Informatics, the team deployed CROW to address the ELN backlog first. Workflow built a custom ELN Import Utility and used it immediately to clear the ~3,000 legacy records — developing and validating the tool on real data simultaneously. The critical technical challenge was the chemistry: reactions exported from CRO ELN systems in .rxn format required a custom clean-up step (combining RDKit and EPAM's Indigo Toolkit) before they could be loaded as genuinely structure-searchable records — not just PDFs — in the company's CDD Vault ELN. Following the backlog clearance, the tool was handed off for the team to operate independently, handling ~30–50 ELN experiments per week from active CRO partners on an ongoing basis.
"This has saved us hours every week."
— Project Lead, undisclosed biotech
Phase 2: Analytical File Automation
A year later, the team returned with the next layer. Analytical files were still manual. Workflow extended the existing utility — rather than starting over — to automate analytical data loading. The tool now scrapes compound and batch IDs from file naming conventions, identifies file types, and loads data into two destinations simultaneously. A second backlog — analytical data for approximately 1,700 compounds — was cleared as part of building and testing the extended capability.
What changed:
- ~3,000 legacy ELN records migrated, chemistry structure-searchable in their own ELN
- ~30–50 ELN experiments per week now processed systematically on an ongoing basis
- Analytical data for ~1,700 compounds cleared from backlog
- Hours per week of manual data processing returned to science
- Distributed team aligned on consistent, high-confidence data — data they can trust
The engagement continues with regular support and ongoing feature development as the team's CRO workflows evolve.